publications
A complete list of my publications. For more information, visit Google Scholar.
2026
- Pol. Gov.
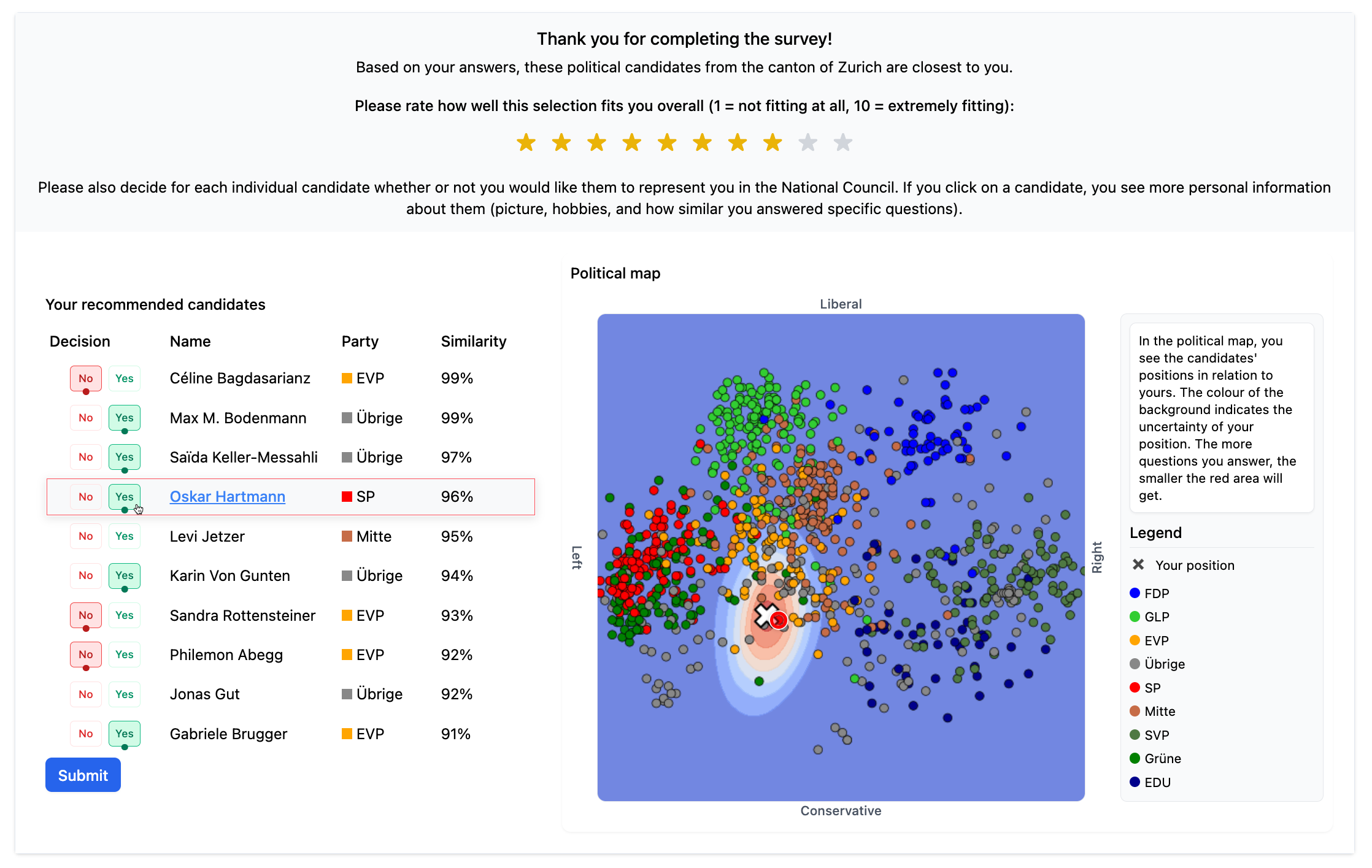 Estimating the Recommendation Certainty in Candidate-based Voting Advice ApplicationsFynn Bachmann, Daan Van Der Weijden, Cristina Sarasua, and Abraham BernsteinPolitics and Governance, Jan 2026
Estimating the Recommendation Certainty in Candidate-based Voting Advice ApplicationsFynn Bachmann, Daan Van Der Weijden, Cristina Sarasua, and Abraham BernsteinPolitics and Governance, Jan 2026Voting Advice Applications (VAAs) typically require users to answer questionnaires before receiving party or candidate recommendations. As users answer more questions, the recommendations naturally become more accurate. However, when users do not complete the questionnaire, the certainty of these recommendations is unknown. In this work, we develop and present a measure to quantify this certainty by introducing an algorithm that estimates the Candidate Recommendation Accuracy (CRA) – the overlap between early and final recommendations – after each question. Through simulations based on existing voter data, we find that our algorithm is more accurate than heuristic estimates. Additionally, it can identify stable recommendations – candidates who are likely to be among the final recommendations – with fewer false positives. Furthermore, we conduct a user experiment investigating different ways of communicating recommendation certainty to users. Our results show that users answer more questions when they see a preview of stable recommendations, but quit the questionnaire earlier when we display an artificially high CRA estimate. Moreover, we find that users appreciate the interface’s simplicity over its accuracy. We conclude that displaying personalized stable recommendations can spark curiosity in VAAs while providing a robust estimate of recommendation certainty for users who submit incomplete questionnaires.
- under review
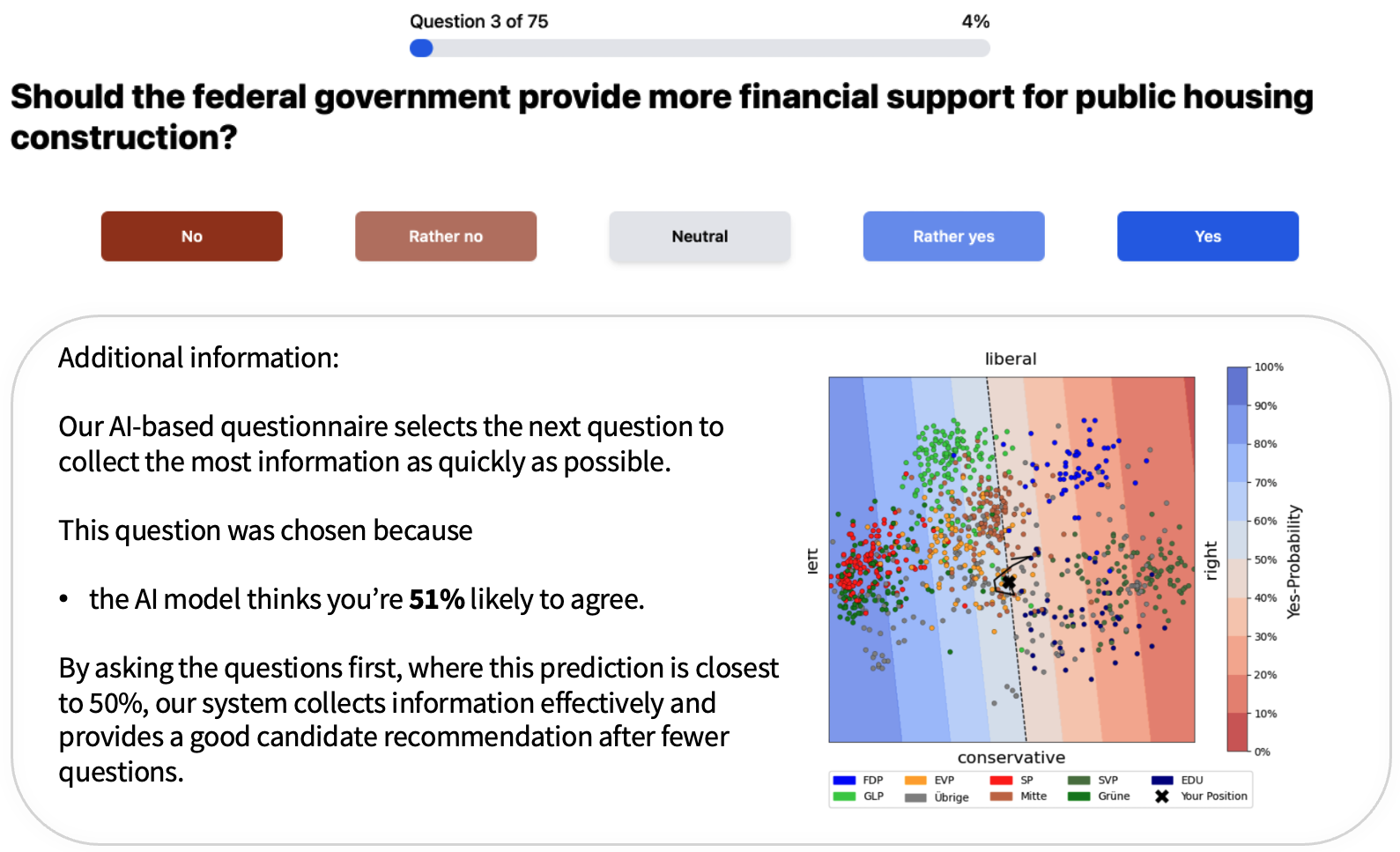 Adaptive Questionnaires for Voting Advice Applications: Three User Experiments on Recommendation Quality, Transparency, and Predictive InfluenceFynn Bachmann, Cristina Sarasua, and Abraham BernsteinWorking paper
Adaptive Questionnaires for Voting Advice Applications: Three User Experiments on Recommendation Quality, Transparency, and Predictive InfluenceFynn Bachmann, Cristina Sarasua, and Abraham BernsteinWorking paperAdaptive Questionnaires (AQs) were recently proposed to accelerate the recommendation process in Voting Advice Applications (VAAs). Often supported by statistical models, AQs select the most informative next question based on users’ individual response profiles, which increases the information gain. However, the user perspective within AQs has been studied to a lesser extent. To address this research gap, we conduct three online experiments focusing on how users (i) assess candidate recommendations, (ii) understand model explanations, and (iii) interpret their predicted responses. Our results show that highly engaged users are more satisfied with recommendations in AQs than in equally long, static questionnaires. While the study also reveals that some users have difficulties understanding the logic of the AQ’s statistical model, we find that they nevertheless rely on its predictions when explicitly displayed in the interface. This evidence suggests that AQs can contribute to political education in VAAs while improving the user experience.
2025
- PLOS One
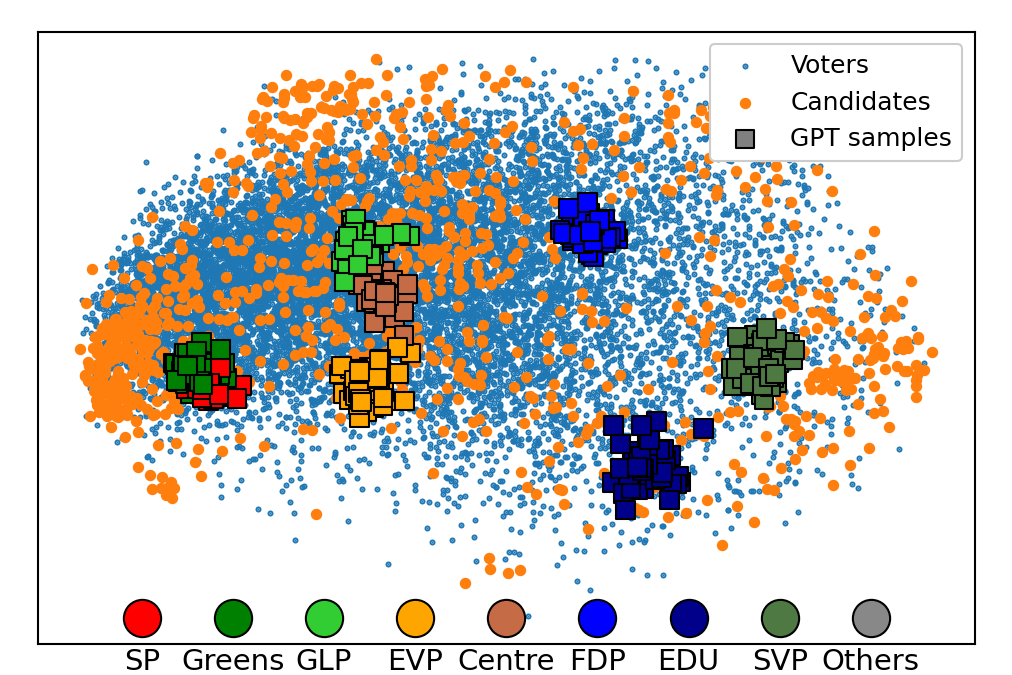 Adaptive political surveys and GPT-4: Tackling the cold start problem with simulated user interactionsFynn Bachmann, Daan Van Der Weijden, Lucien Heitz, Cristina Sarasua, and Abraham BernsteinPLoS One, May 2025
Adaptive political surveys and GPT-4: Tackling the cold start problem with simulated user interactionsFynn Bachmann, Daan Van Der Weijden, Lucien Heitz, Cristina Sarasua, and Abraham BernsteinPLoS One, May 2025Adaptive questionnaires dynamically select the next question for a survey participant based on their previous answers. Due to digitalisation, they have become a viable alternative to traditional surveys in application areas such as political science. One limitation, however, is their dependency on data to train the model for question selection. Often, such training data (i.e., user interactions) are unavailable a priori. To address this problem, we (i) test whether Large Language Models (LLM) can accurately generate such interaction data and (ii) explore if these synthetic data can be used to pre-train the statistical model of an adaptive political survey. To evaluate this approach, we utilise existing data from the Swiss Voting Advice Application (VAA) Smartvote in two ways: First, we compare the distribution of LLM-generated synthetic data to the real distribution to assess its similarity. Second, we compare the performance of an adaptive questionnaire that is randomly initialised with one pre-trained on synthetic data to assess their suitability for training. We benchmark these results against an “oracle” questionnaire with perfect prior knowledge. We find that an off-the-shelf LLM (GPT-4) accurately generates answers to the Smartvote questionnaire from the perspective of different Swiss parties. Furthermore, we demonstrate that initialising the statistical model with synthetic data can (i) significantly reduce the error in predicting user responses and (ii) increase the candidate recommendation accuracy of the VAA. Our work emphasises the considerable potential of LLMs to create training data to improve the data collection process in adaptive questionnaires in LLM-affine areas such as political surveys.
- ACM FAccT
 Bridging Voting and Deliberation with Algorithms: Field Insights from vTaiwan and Kultur KomiteeJoshua C. Yang and Fynn BachmannIn Proceedings of the 2025 ACM Conference on Fairness, Accountability, and TransparencyPresented at FAccT 2025 in Athens, Greece
Bridging Voting and Deliberation with Algorithms: Field Insights from vTaiwan and Kultur KomiteeJoshua C. Yang and Fynn BachmannIn Proceedings of the 2025 ACM Conference on Fairness, Accountability, and TransparencyPresented at FAccT 2025 in Athens, GreeceDemocratic processes increasingly integrate large-scale voting with face-to-face deliberation to reconcile individual preferences with collective decision-making. This work introduces algorithmic methods to bridge online voting with face-to-face deliberation, tested in two real-world scenarios: Kultur Komitee 2024 (KK24) and vTaiwan. We present three key contributions: (1) Preference-based Clustering for Deliberation (PCD), enabling both focused and broad discussions by computing balanced homogeneous and heterogeneous groups; (2) Humanin-the-loop MES, enhancing the Method of Equal Shares algorithm with real-time feedback, giving participants control over algorithmic decision-making; and (3) the ReadTheRoom method, using opinion mapping to identify agreement and divergence while tracking opinion shifts during deliberation. These actionable frameworks extend in-person deliberation with scalable digital methods that address the complexities of modern participatory decision-making.
2024
- ECML/PKDD
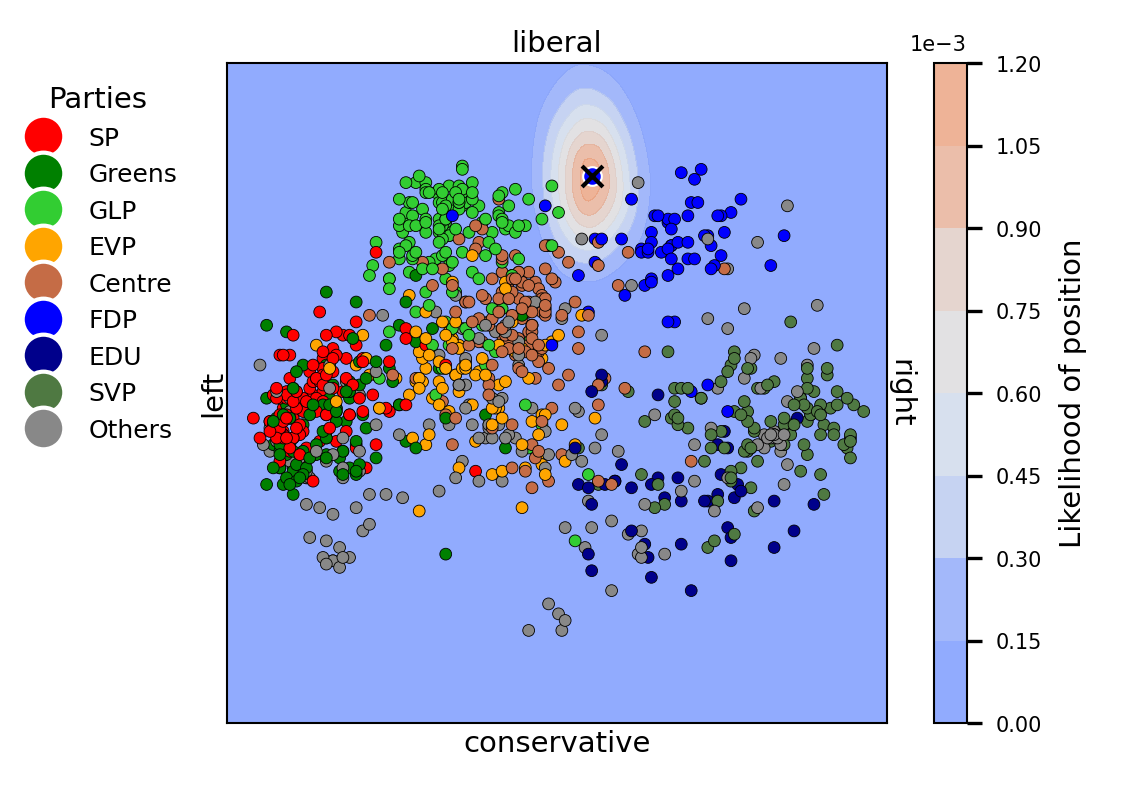 Fast and Adaptive Questionnaires for Voting Advice ApplicationsFynn Bachmann, Cristina Sarasua, and Abraham BernsteinIn Machine Learning and Knowledge Discovery in Databases. Applied Data Science TrackPresented at ECML 2024 in Vilnius, Lithuania
Fast and Adaptive Questionnaires for Voting Advice ApplicationsFynn Bachmann, Cristina Sarasua, and Abraham BernsteinIn Machine Learning and Knowledge Discovery in Databases. Applied Data Science TrackPresented at ECML 2024 in Vilnius, LithuaniaThe effectiveness of Voting Advice Applications is often compromised by the length of their questionnaires. To address user fatigue and incomplete responses, some applications (such as the Swiss Smartvote) offer a condensed version of their questionnaire. However, these condensed versions cannot ensure the accuracy of recommended parties or candidates, which we show to remain below 40%. To address these limitations, this work introduces an adaptive questionnaire approach that selects subsequent questions based on users’ previous answers, aiming to enhance recommendation accuracy while reducing the number of questions posed to the voters. Our method uses an encoder and decoder module to predict missing values at any completion stage, leveraging a two-dimensional latent space that is reflective of the traditional methods used in political science for visualizing ideology. Additionally, a selector module is proposed to determine the most informative subsequent question based on the voter’s current position in the latent space and the remaining unanswered questions. We validated our approach using the Smartvote dataset from the Swiss Federal elections in 2019, testing various spatial models and selection methods to optimize the system’s predictive accuracy. Our findings indicate that employing the IDEAL model both as encoder and decoder, combined with a PosteriorRMSE method for question selection, significantly improves the accuracy of recommendations, achieving 74% accuracy after asking the same number of questions as in the condensed version.
2023
- ECML/PKDD
 Wasserstein t-SNEFynn Bachmann, Philipp Hennig, and Dmitry KobakIn Machine Learning and Knowledge Discovery in DatabasesPresented at ECML 2022 in Grenoble, France
Wasserstein t-SNEFynn Bachmann, Philipp Hennig, and Dmitry KobakIn Machine Learning and Knowledge Discovery in DatabasesPresented at ECML 2022 in Grenoble, FranceScientific datasets often have hierarchical structure: for example, in surveys, individual participants (samples) might be grouped at a higher level (units) such as their geographical region. In these settings, the interest is often in exploring the structure on the unit level rather than on the sample level. Units can be compared based on the distance between their means, however this ignores the within-unit distribution of samples. Here we develop an approach for exploratory analysis of hierarchical datasets using the Wasserstein distance metric that takes into account the shapes of within-unit distributions. We use tSNE to construct 2D embeddings of the units, based on the matrix of pairwise Wasserstein distances between them. The distance matrix can be efficiently computed by approximating each unit with a Gaussian distribution, but we also provide a scalable method to compute exact Wasserstein distances. We use synthetic data to demonstrate the effectiveness of our Wasserstein t-SNE, and apply it to data from the 2017 German parliamentary election, considering polling stations as samples and voting districts as units. The resulting embedding uncovers meaningful structure in the data.